Table of Contents
Open Table of Contents
Introduction
Powerful AI models are heavily post-trained for reasoning, coding tasks, agentic capabilities like instruction-following and tool calling. In fact, one of the hypotheses of why Claude Code (CLI) is better is that the model is post-trained on tools that the harness(Claude Code) uses making the full stack (harness + model) even better. It’s the result of deliberate post-training using techniques like Supervised Fine-Tuning (SFT), Reinforcement Learning from Human Feedback (RLHF), and Direct Preference Optimization (DPO).
*I wanted to understand this process hands-on. In this blog, I’ll walk you through my journey fine-tuning Qwen3-0.6B on HuggingFace CodeForces using its cloud infrastructure and HF model-trainer claude skill and Claude Code.
We will try Supervised Fine-Tuning (SFT) today.
What We’re Doing
- Base Model: Qwen3-0.6B
- CodeForces Competition Problems Dataset: The open-r1/codeforces-cots dataset contains 47,000 competitive programming problems with solutions and chain-of-thought reasoning traces. Each example has: Problem description: A competitive programming challenge, Messages format: Conversational format with the problem as a user message and the solution with reasoning as an assistant message. Example:
Problem :
You are given an array a of n integers, where n is odd. In one operation, you will remove two adjacent elements from the array a, and then concatenate the remaining parts. For example, given the array [4,7,4,2,9], we can obtain [4,2,9] by removing [4,7].You will repeatedly perform this operation until exactly one element remains in a. Find the maximum possible value of the remaining element.
Messages:
{
"messages": [
{
"role": "user",
"content": "You will be given a competitive programming problem. Please reason step by step about the solution, then provide a complete implementation in C++17..."
},
{
"role": "assistant",
"content": "Let's think through this step by step...\n\n```cpp\n\n```"
}
]
}- Using HuggingFace Infrastructure & Tools (model-trainer skill and HF MCP)
- Hugging Face Jobs: Cloud GPU infrastructure (requires HF Pro account)
- TRL (Transformer Reinforcement Learning): The library that actually handles the training loop, LoRA integration, and optimization
- HF Model-Trainer Skill : https://github.com/huggingface/skills/tree/main/hf-llm-trainer/skills/model-trainer
Claude Code + HF MCP helps in coding the fine-tuning script, monitoring and pushing metrics, runs jobs in the HF GPU infra.
Keywords
| Terms | Definitions |
|---|---|
| Supervised Fine-Tuning (SFT) | The pre-trained model (like Qwen3) has broad knowledge from internet text. SFT teaches it task-specific skills by showing it examples of correct behavior. : Understand competitive programming problems, Reason through solution approaches, Generate correct C++ code, Explain the solution clearly |
| LoRA: Efficient Fine-Tuning | Qwen3-0.6B has 600 million parameters. LoRA (Low rank adaptation) doesn’t modify the original model weights. Instead, it add a small “adapter” layer that learns tasks-specific transformations. Finally, we only train about 1% of the total parameters, but still achieve effective learning. The adapters captures the task-specific patterns while the frozen base model retains general knowledge. |
Key Hyper-parameters
| Parameter | Value | What It Does | Why This Value? |
|---|---|---|---|
| Batch Size | 2 (per GPU) | Examples processed simultaneously | Memory-efficient for 24GB GPU |
| Epochs | 3 | Full passes through the training data to optimise the evaluation | Multiple passes help with 1,000 |
Model Evaluation Parameters
How do we evaluate the fine-tuned model.
| Metric | Definition |
|---|---|
| Training loss | Measures how well the model predicts tokens on the training data |
| Validation loss | Measures how well the model predicts tokens on unseen evaluation data to check generalization |
| Token Accuracy on eval set | Model predicts next tokens and we compare with the ground truth |
Fine-tuning Implementation
- First run, a sample fine-tuning run on 500 examples with 1 epoch
- Second run, fine-tuning run with 1000 examples and 3 epochs
First goal was seeing a training job complete successfully. I started with just 500 examples for rapid iteration.
Early attempts had lot of failures:
- ❌ Missing dependencies (
trl,peft,bitsandbytes) - ❌ Format detection errors
- ❌ Job timeouts from underestimating training time
- ❌ Errors with
KeyError: 'completion'
Key learnings:
- Dataset format: The TRL library was getting confused with
messagesandpromptcolumns in the dataset. SFTTrainer saw'prompt'in the first example and assumed prompt-completion format. Then it looked for'completion'—which didn’t exist—and crashed. - Use Python UV script format:: Inline dependencies in script comments. Jobs can’t access local files
Finally, ran on 1000 examples with train-eval split
Here is the code : https://gist.github.com/kn-neeraj/140c2184233d922be0c2cb92d21dfa00
Results & Interpretation
| Metric | 500 Examples (1 epoch) | 1000 Examples (3 epochs) train-eval | Improvement |
|---|---|---|---|
| Final Loss | training loss: 1.1328 | training loss : 0.85 evaluation loss : 0.35 | 65% better |
| Token Accuracy | training: 75% | training : 78% evaluation : 89% | +14% |
| Training Time | ~7 min | ~18 min | 2.6x longer |
Loss Function Graphs from the run
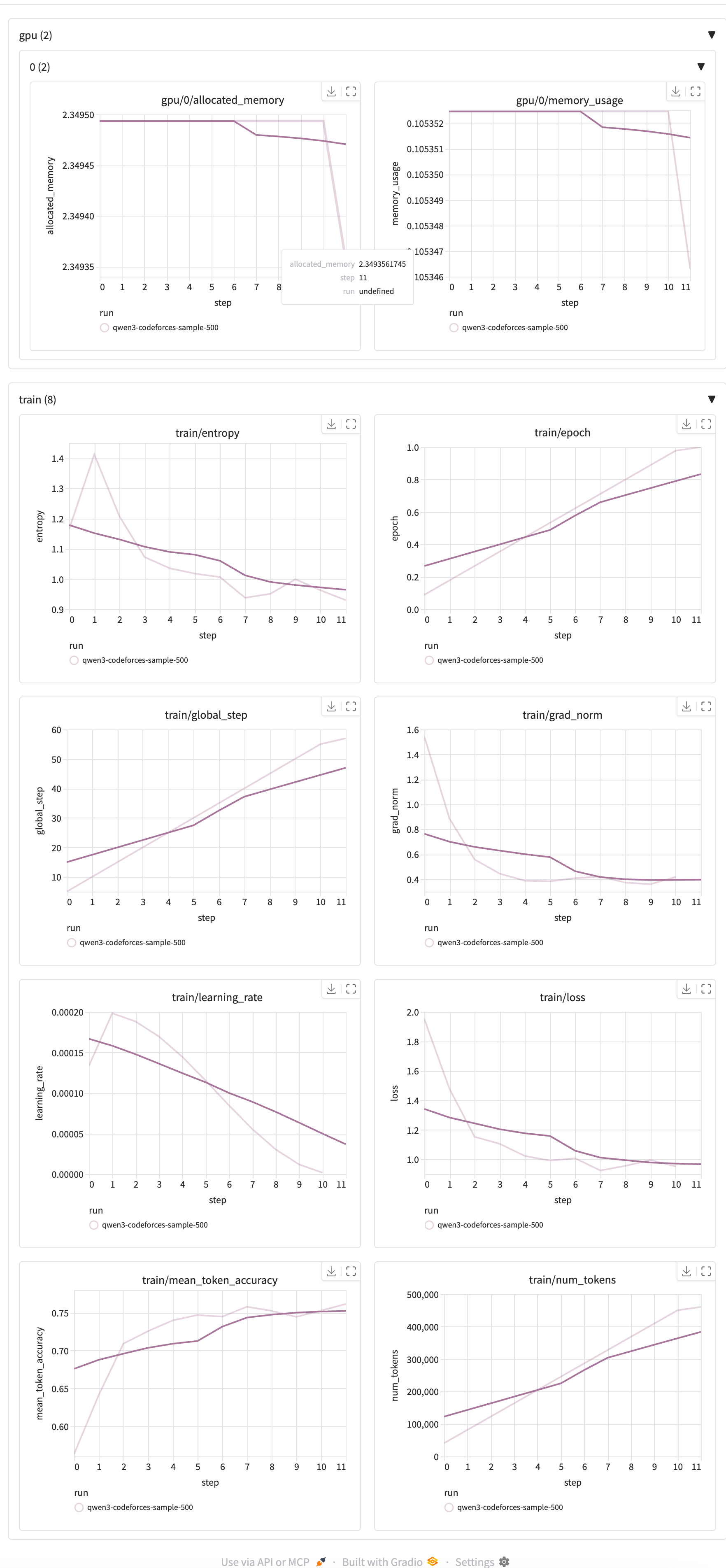
Observations:
- Both train and eval loss decreased together, good for generalization
- Eval metrics were slightly worse than train (expected), but the gap was small
- No signs of severe overfitting even after 3 epochs. Need more epochs
- GPU memory: Still only ~10-12% utilized
The model was genuinely learning to solve new problems, not just memorizing the training set.
Key Learnings & What Next!
Learning 1 -> Claude Code with HF MCP & model-trainer skill works but with a lot of context. HF MCP gives claude tools like below to help in full cycle of fine-tuning:
mcp__hf-skills__hf_jobs- Submit training jobs to cloud GPUsmcp__hf-skills__model_search- Find models on the Hubmcp__hf-skills__dataset_search- Discover datasetsmcp__hf-skills__hub_repo_details- Get model/dataset info
Claude Code helped write training script and use HF MCP to submit the training jobs.
What’s Next -> Doing fine-tuning run on full dataset (47000 examples) and doing evaluation on benchmark dataset using LLM-as-a-judge.
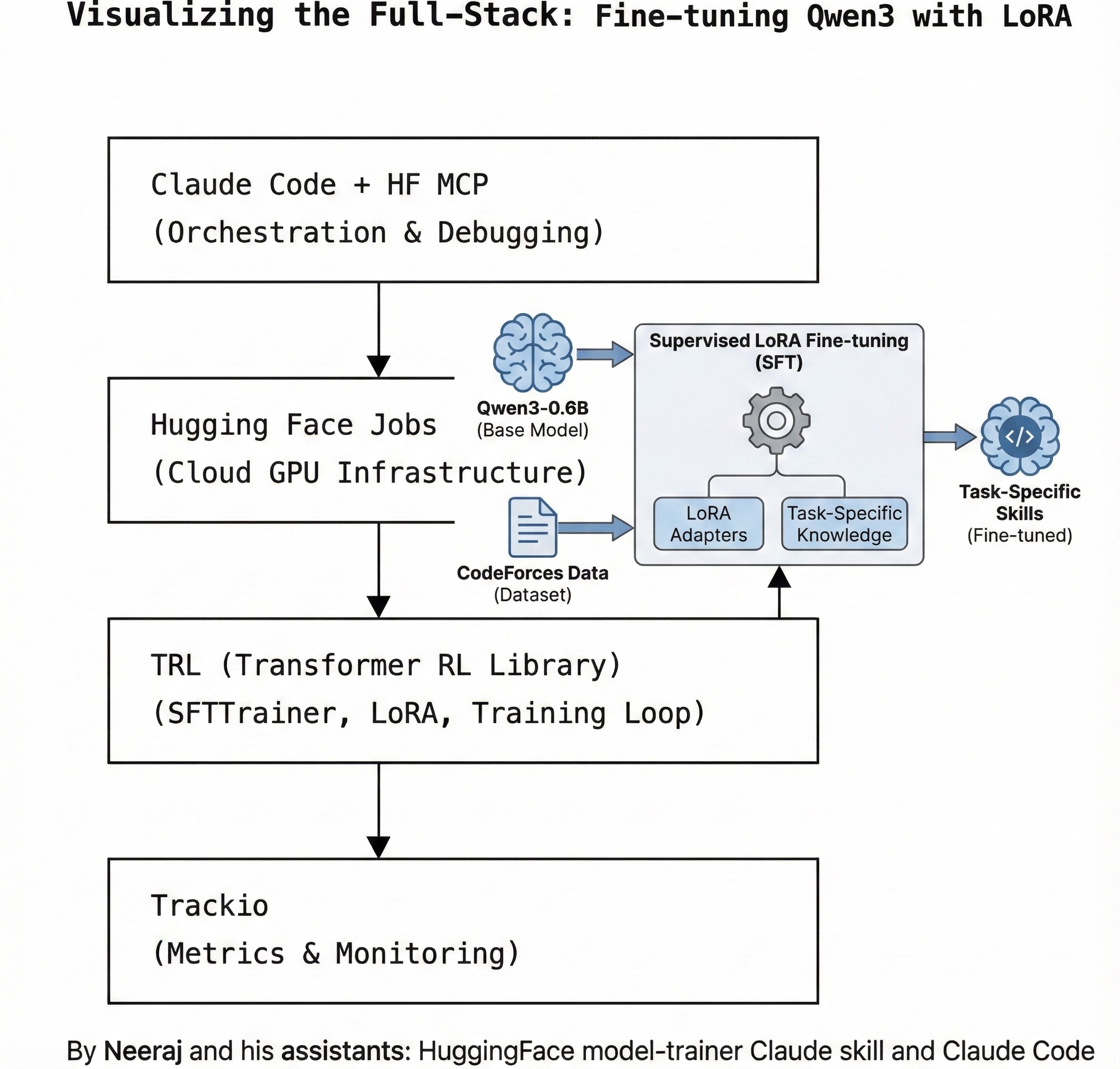
Visualising the Full Stack
┌─────────────────────────────────────────┐
│ Claude Code + HF MCP │
│ (Orchestration & Debugging) │
└───────────────┬─────────────────────────┘
│
┌───────────────▼─────────────────────────┐
│ Hugging Face Jobs │
│ (Cloud GPU Infrastructure) │
└───────────────┬─────────────────────────┘
│
┌───────────────▼─────────────────────────┐
│ TRL (Transformer RL Library) │
│ (SFTTrainer, LoRA, Training Loop) │
└───────────────┬─────────────────────────┘
│
┌───────────────▼─────────────────────────┐
│ Trackio │
│ (Metrics & Monitoring) │
└─────────────────────────────────────────┘Key References
- Hugging Face TRL Docs
- Claude model-trainer skill so we can guide claude code to do most of the heavy lifting https://github.com/huggingface/skills/tree/main/hf-llm-trainer/skills/model-trainer